

Короткие байты: Глубокое обучение — это область применения глубоких нейронных сетей для изучения функции. И Глубокие Нейронные Сети — это в основном Нейронные Сети с более чем одним Скрытым слоем. В этом посте я попытаюсь представить Глубокое обучение более увлекательно, не вдаваясь в математические детали.
Немного истории искусственного интеллекта
Когда началась область искусственного интеллекта, все исследователи были сосредоточены на «решении» проблемы, поскольку именно так они обучались. Например, автоматический поиск решения лабиринта. Смена парадигмы мышления должна была произойти до того, как люди начали подходить к проблемам по-другому.
Новый подход состоял не в том, чтобы решить задачу, а в том, чтобы «подражать» ее решению. Не все проблемы могут быть решены. Это было известно математикам ранее. Что ж, нужно посмотреть, что представляет собой решение. Например,
У него не было решений до введения концепции комплексных чисел. Но есть и другие проблемы, которые действительно неразрешимы (в некотором смысле). Проблемы реального мира слишком сложны, чтобы найти решение. Таким образом, концепция «подражания» требовалась для решения очень сложных задач реального мира. Лучшим примером для сравнения этих двух парадигм являются компьютер Deep Blue, который победил Каспарова в 1996 году, и компьютер AlphaGo, который победил Ли Седола в 2016 году. Первый «ищет» лучший ход в шахматах, а второй «подражает» сильному игрок го
Рекомендуемые: Введение в аппаратную архитектуру для глубокого обучения
Доказательство того, что что-то можно «выучить» —
Без сильной математической поддержки продвижение вперед в области исследований не имеет смысла. Итак, задачи были переведены в математические задачи, и «имитация» решения была переведена в «подгонку» функции.
Итак, все ли функции могут быть «установлены»? Как выясняется, «Да!» Или, по крайней мере, большинство функций, которые нам нужны для решения реальных проблем. Это называется универсальной теоремой приближения (UAT). Но это требовало определенной архитектуры, которую мы сейчас называем Нейронная сеть. Таким образом, была разработана архитектура, которая гарантирует, что любая функция может быть приспособлена с любой точностью. Некоторые интересные наблюдения об архитектуре были —
- Набор дискретных входов мог соответствовать даже непрерывным функциям (то есть функциям без резких скачков).
- Необходим как минимум еще один слой (называемый скрытым слоем) таких дискретных узлов.
- Информация от одного узла может быть возвращена в качестве входных данных, как механизм обратной связи.
- Некоторая «нелинейность» должна была быть включена в сеть (так называемая функция активации).

Подражание и угадывание —
Одна из проблем описанного выше метода «подгонки» заключается в том, что мы должны знать, как выглядит решение проблемы. Это поднимает другой вопрос: если мы знаем решение, зачем вообще его подгонять? Ответ на этот вопрос двоякий — 1) Вычисление точного решения может быть гораздо более сложным в вычислительном отношении 2) Многие из современных проблем ИИ в современном мире должны имитировать поведение и задачи человека.
Но первая проблема все еще сохраняется. Мы должны знать решение заранее. Чтобы решить задачу без решения, компьютер должен «угадать», образованный «догадаться». Следовательно, в классе «проблем с обучением» происходит бифуркация — имитация и угадывание. Первый называется ‘Контролируемое обучение‘И последний‘Обучение без учителя«. Примером неконтролируемого обучения может быть кластеризация набора данных на основе некоторого атрибута. Эти методы в совокупности называются машинным обучением.
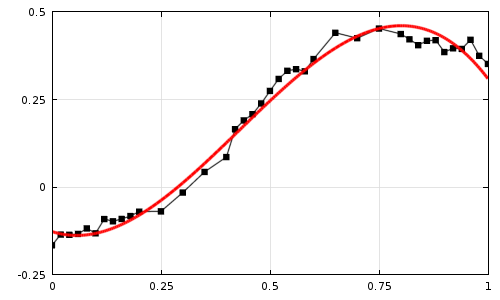
 Рис 1: контролируемое обучение
Рис 1: контролируемое обучение Рис 2: обучение без учителя
Рис 2: обучение без учителя
В контролируемом обучении были заданы точки данных (красный), и сеть научилась соответствовать функции (синий), в данном случае функции sinc. При неконтролируемом обучении было дано только изображение, и сети было приказано классифицировать изображение по цвету каждого пикселя на 8 кластеров. Как видно, сеть хорошо справляется с кластеризацией пикселей.
Углубление нейронных сетей —
Итак, что же такого глубокого в глубоких нейронных сетях? Глубокие нейронные сети — это в основном нейронные сети с более чем одним скрытым слоем. Таким образом, они выглядят «шире», чем «глубже». Здесь есть несколько вопросов, на которые нужно ответить —
Если сеть из одного скрытого слоя может приближаться к какой-либо функции (UAT), зачем добавлять несколько слоев? Это один из фундаментальных вопросов. Каждый скрытый слой действует как «экстрактор объектов». Если у нас есть только один скрытый слой, возникают две проблемы:
- Возможности извлечения функций в сети намного меньше, что означает, что мы должны предоставлять подходящие функции для сети. Это добавляет операцию извлечения функции, специфичную для этого приложения. Поэтому сеть в некоторой степени теряет способность изучать различные функции и не может называться «автоматической».
- Даже для изучения предоставляемых функций количество узлов в скрытых слоях растет экспоненциально, что вызывает арифметические проблемы при обучении.
Чтобы решить эту проблему, нам нужна сеть, чтобы самостоятельно изучить функции. Поэтому мы добавляем несколько скрытых слоев, каждый с меньшим количеством узлов. Итак, насколько хорошо это работает? Эти Глубокие Нейронные Сети научились играть в игры Atari, просто глядя на изображения с экрана.
Прыжок (ы) —
Итак, почему и как Deep Learning стал настолько успешным в последние годы? Что касается того, почему, революционные идеи были сделаны в алгоритмах глубокого обучения в 1990-х годах доктором Гоффри Хинтоном. Что касается того, как часть, многие факторы были ответственны. Много наборов данных были доступны. Аппаратные архитектуры были улучшены. Библиотеки программного обеспечения были построены. Большие успехи в области выпуклой оптимизации.
Поступайте с осторожностью —
Относительно недавнее открытие показывает, что эти глубоко обученные модели были очень уязвимы для атак. DNN являются успешными, если нет никаких неблагоприятных воздействий на данные. Следующее изображение иллюстрирует это —

Эта уязвимость вызвана тем, что модель очень чувствительна к функциям. Человечески незаметные изменения функций могут полностью разрушить сеть от обучения. Были предложены новые модели, называемые Adversarial Networks, но это история для другого дня. Другим частым эффектом является перенастройка данных, что может привести к высокой точности обучения, но очень низкой производительности во время тестирования.
Итак, что вы думаете о будущем глубокого обучения? Каковы некоторые открытые проблемы в Deep Learning? Прокомментируйте и поделитесь этим с нами.
Рекомендуемые: Введение в аппаратную архитектуру для глубокого обучения



