 Короткие байты: Web-сканер — это программа, которая просматривает Интернет (World Wide Web) заранее определенным, настраиваемым и автоматическим способом и выполняет заданные действия с просканированным контентом. Поисковые системы, такие как Google и Yahoo, используют паук как средство предоставления актуальных данных.
Короткие байты: Web-сканер — это программа, которая просматривает Интернет (World Wide Web) заранее определенным, настраиваемым и автоматическим способом и выполняет заданные действия с просканированным контентом. Поисковые системы, такие как Google и Yahoo, используют паук как средство предоставления актуальных данных.
12 августа 2015 г. компания Webhose.io, предоставляющая прямой доступ к оперативным данным с сотен тысяч форумов, новостей и блогов, опубликовала статьи, описывающие крошечный многопоточный веб-сканер, написанный на python. Этот поисковый робот Python способен сканировать весь Интернет для вас. Ран Гева, автор этого крошечного поискового робота, говорит, что:
Я написал как «Грязный», «Иффи», «Плохо», «Не очень хорошо». Я говорю, он выполняет свою работу и загружает тысячи страниц с нескольких страниц за считанные часы. Никакой настройки не требуется, никакого внешнего импорта, просто запустите следующий код Python с начальным сайтом и бездельничайте (или займитесь чем-нибудь другим, потому что это может занять несколько часов или дней, в зависимости от того, сколько данных вам нужно).
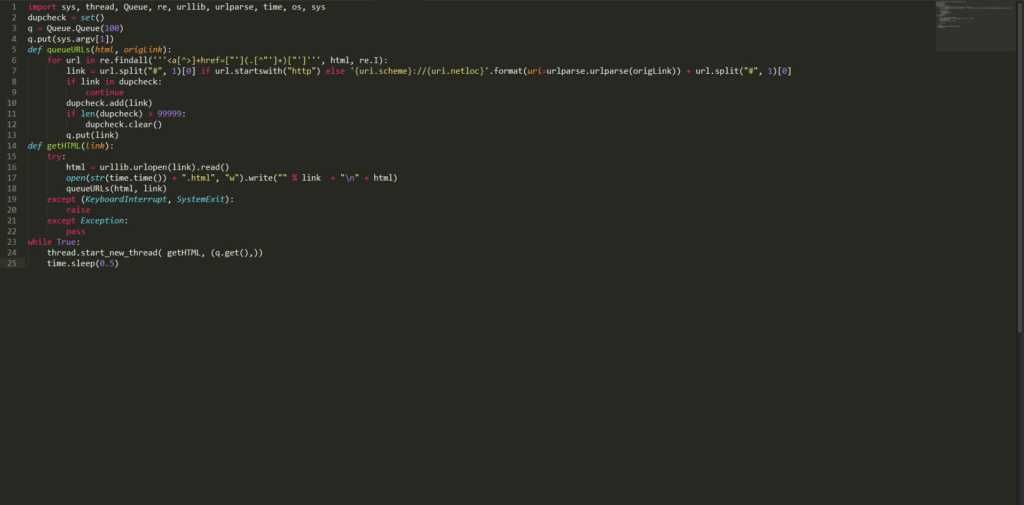
Многопоточный сканер на основе Python довольно прост и очень быстр. Он способен обнаруживать и удалять дубликаты ссылок и сохранять источник и ссылку, которые впоследствии могут быть использованы при поиске входящих и исходящих ссылок для расчета рейтинга страницы. Это абсолютно бесплатно, и код указан ниже:
импорт sys, поток, очередь, ре, urllib, urlparse, время, ОС, sys
dupcheck = set ()
q = Queue.Queue (100)
q.put (sys.argv [1])
def queueURLs (html, origLink):
для URL в re.findall ('' '] + href = ["'] (. [^" '] +) ["'] '' ', html, re.I):
link = url.split ("#", 1) [0], если url.startswith ("http") else '{uri.scheme}: // {uri.netloc}' .format (uri = urlparse.urlparse (origLink) )) + url.split ("#", 1) [0]
если ссылка в дупчеке:
Продолжить
dupcheck.add (ссылка)
если len (dupcheck)> 99999:
dupcheck.clear ()
q.put (ссылка)
def getHTML (ссылка):
пытаться:
html = urllib.urlopen (ссылка) .read ()
open (str (time.time ()) + ".html", "w"). write (""% link + "\ n" + html)
queueURLs (html, ссылка)
кроме (KeyboardInterrupt, SystemExit):
повышение
кроме исключения:
проходят
пока верно:
thread.start_new_thread (getHTML, (q.get (),))
time.sleep (0,5)Сохраните приведенный выше код с некоторым именем, скажем, «myPythonCrawler.py». Чтобы начать сканирование любого веб-сайта, просто введите:
$ python myPythonCrawler.py http://fossbytes.com
Расслабьтесь и наслаждайтесь этим веб-сканером в python. Он загрузит весь сайт для вас.
Стать профессионалом в Python с этими курсами
Вам нравится этот мертвый простой многопоточный веб-сканер на Python? Дайте нам знать в комментариях.
Также прочитайте: Как создать загрузочный USB без какого-либо программного обеспечения в Windows 10